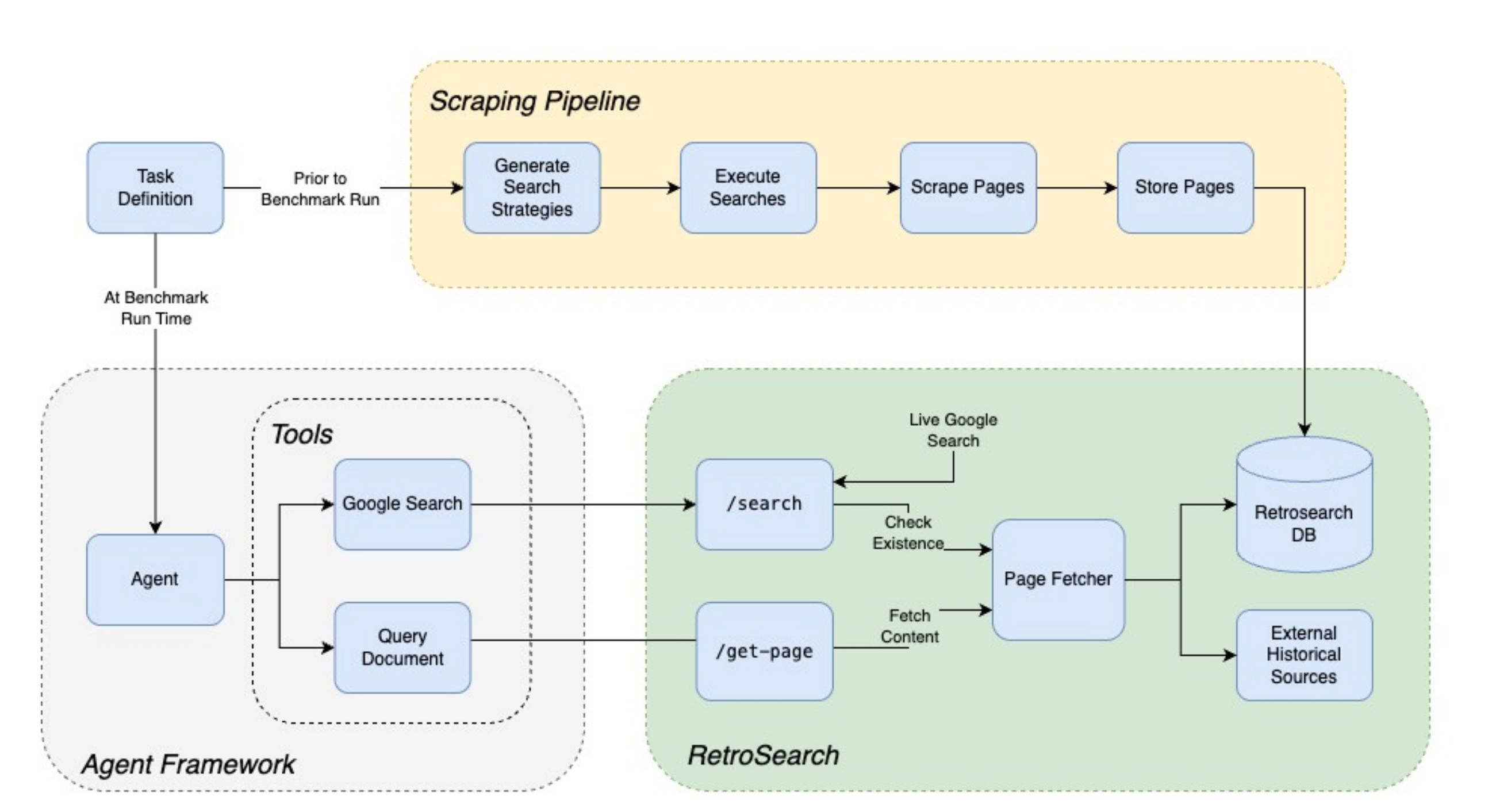
Bench to the Future (BTF) is a second benchmark, separate from DRB, designed to evaluate the ability of LLM agents to make predictions on messy, real-world forecasting questions. For full details, see the Bench to the Future paper.
Methods
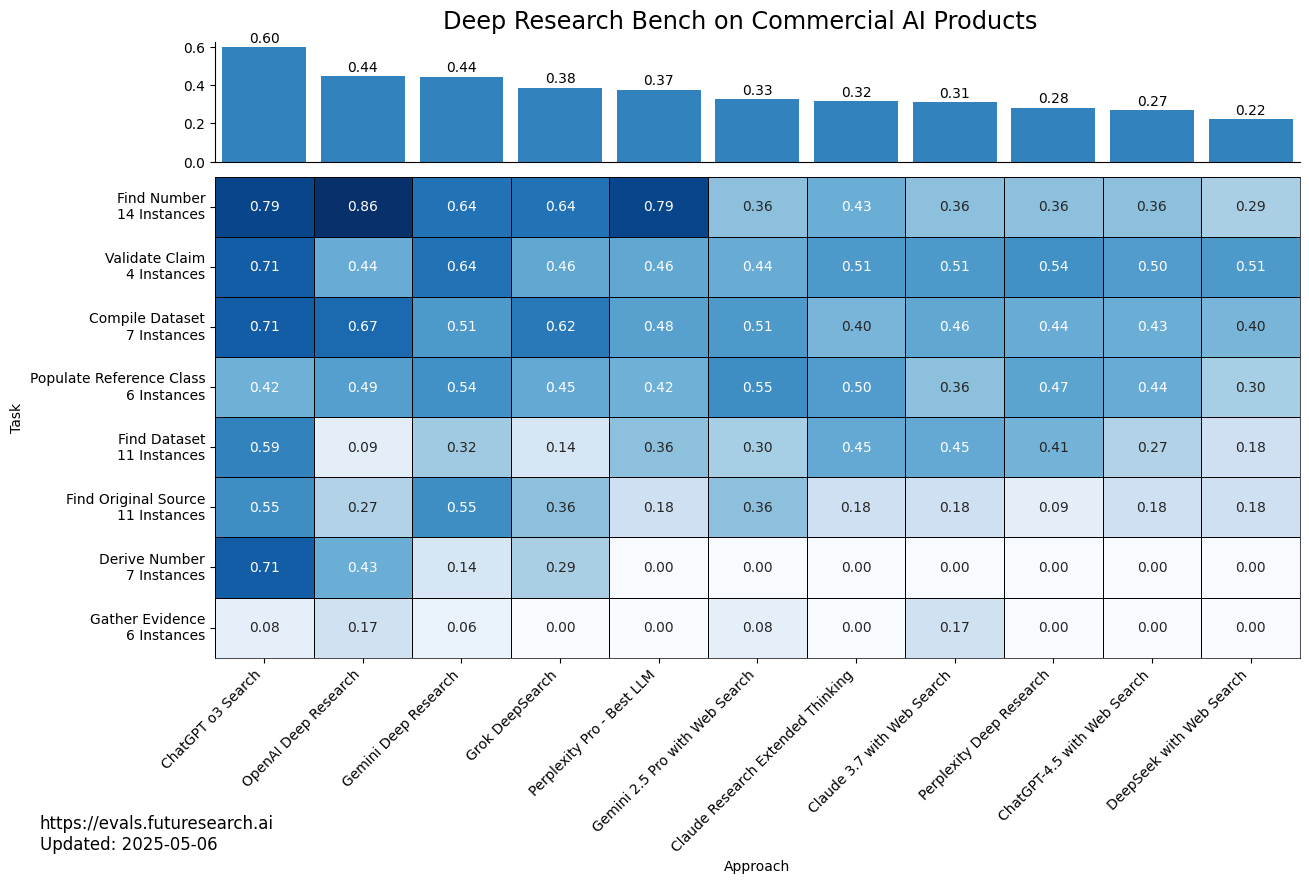
Forecasting is a challenging task that offers a clearly measurable way to study AI systems. It requires a large amount of research on the internet, as well as good judgement to weigh and interpret available evidence.
Bench To the Future (BTF) is a "pastcasting" benchmark with hundreds of questions for which the resolution is already known. Each question is accompanied by a large offline corpus of tens of thousands of relevant web pages, enabling a way to elicit realistic "forecasts" on past events from LLMs.
We invite researchers to contact us at hello@futuresearch.ai to utilize our benchmark or tooling for their own research.